Глава 21: Исследование и Открытие
В этой главе рассматриваются шаблоны, которые позволяют интеллектуальным агентам активно искать новую информацию, раскрывать новые возможности и выявлять неизвестные неизвестные в своей операционной среде. Исследование и открытие отличаются от реактивного поведения или оптимизации в рамках заранее определенного пространства решений. Вместо этого они сосредоточены на том, чтобы агенты проактивно исследовали незнакомые территории, экспериментировали с новыми подходами и генерировали новые знания или понимание. Этот шаблон имеет решающее значение для агентов, работающих в открытых, сложных или быстро развивающихся областях, где статических знаний или заранее запрограммированных решений недостаточно. Он подчеркивает способность агента расширять свое понимание и возможности.
Практические применения и случаи использования
AI агенты обладают способностью интеллектуально расставлять приоритеты и исследовать, что приводит к применению в различных областях. Автономно оценивая и упорядочивая потенциальные действия, эти агенты могут навигировать в сложных средах, раскрывать скрытые инсайты и стимулировать инновации. Эта способность к приоритизированному исследованию позволяет им оптимизировать процессы, открывать новые знания и генерировать контент.
Примеры:
Автоматизация научных исследований: Агент разрабатывает и проводит эксперименты, анализирует результаты и формулирует новые гипотезы для открытия новых материалов, кандидатов на лекарственные препараты или научных принципов.
Игровые стратегии и генерация стратегий: Агенты исследуют игровые состояния, обнаруживая эмерджентные стратегии или выявляя уязвимости в игровых средах (например, AlphaGo).
Исследование рынка и выявление трендов: Агенты сканируют неструктурированные данные (социальные сети, новости, отчеты) для выявления трендов, поведения потребителей или рыночных возможностей.
Обнаружение уязвимостей безопасности: Агенты исследуют системы или кодовые базы для поиска недостатков безопасности или векторов атак.
Генерация творческого контента: Агенты исследуют комбинации стилей, тем или данных для создания художественных произведений, музыкальных композиций или литературных работ.
Персонализированное образование и обучение: AI наставники расставляют приоритеты в путях обучения и доставке контента на основе прогресса студента, стиля обучения и областей, требующих улучшения.
Google Co-Scientist
AI со-ученый - это AI система, разработанная Google Research и предназначенная как вычислительный научный коллаборатор. Она помогает человеческим ученым в аспектах исследований, таких как генерация гипотез, уточнение предложений и экспериментальный дизайн. Эта система работает на основе Gemini LLM.
Разработка AI со-ученого решает проблемы в научных исследованиях. К ним относятся обработка больших объемов информации, генерация проверяемых гипотез и управление экспериментальным планированием. AI со-ученый поддерживает исследователей, выполняя задачи, которые включают крупномасштабную обработку и синтез информации, потенциально раскрывая взаимосвязи в данных. Его цель - дополнить человеческие когнитивные процессы путем обработки вычислительно сложных аспектов ранних стадий исследований.
Архитектура системы и методология: Архитектура AI со-ученого основана на multi-agent фреймворке, структурированном для эмуляции коллаборативных и итеративных процессов. Этот дизайн интегрирует специализированных AI агентов, каждый из которых имеет определенную роль в достижении исследовательской цели. Агент-супервизор управляет и координирует деятельность этих индивидуальных агентов в рамках асинхронного фреймворка выполнения задач, который позволяет гибкое масштабирование вычислительных ресурсов.
Основные агенты и их функции включают (см. Рис. 1):
Generation agent: Инициирует процесс путем создания начальных гипотез через исследование литературы и симулированные научные дебаты.
Reflection agent: Действует как рецензент, критически оценивая корректность, новизну и качество сгенерированных гипотез.
Ranking agent: Использует турнир на основе Elo для сравнения, ранжирования и приоритизации гипотез через симулированные научные дебаты.
Evolution agent: Непрерывно уточняет топ-ранжированные гипотезы путем упрощения концепций, синтеза идей и исследования нетрадиционных рассуждений.
Proximity agent: Вычисляет граф близости для кластеризации похожих идей и помощи в исследовании ландшафта гипотез.
Meta-review agent: Синтезирует инсайты из всех обзоров и дебатов для выявления общих паттернов и предоставления обратной связи, позволяя системе непрерывно улучшаться.
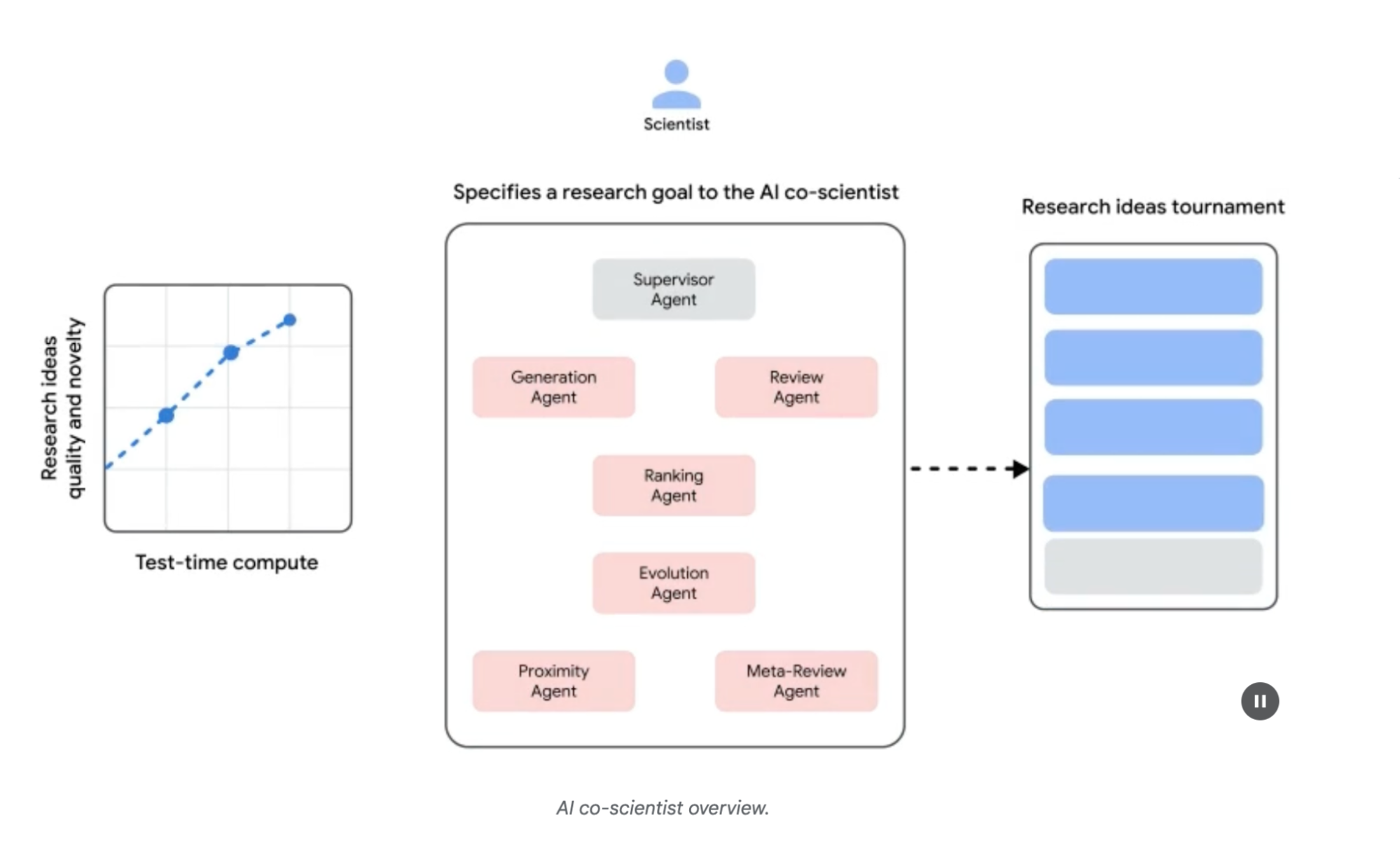 Рис. 1: (С разрешения авторов) AI Co-Scientist: От идеации к валидации
Рис. 1: (С разрешения авторов) AI Co-Scientist: От идеации к валидации
Операционная основа системы опирается на Gemini, который обеспечивает понимание языка, рассуждение и генеративные способности. Система включает "test-time compute scaling" - механизм, который выделяет увеличенные вычислительные ресурсы для итеративного рассуждения и улучшения выходных данных. Система обрабатывает и синтезирует информацию из различных источников, включая академическую литературу, веб-данные и базы данных.
Система следует итеративному подходу "генерировать, дебатировать и развивать", отражающему научный метод. После ввода научной проблемы от человека-ученого, система участвует в самосовершенствующемся цикле генерации гипотез, оценки и уточнения. Гипотезы проходят систематическую оценку, включая внутренние оценки среди агентов и механизм ранжирования на основе турниров.
Валидация и результаты: Полезность AI со-ученого была продемонстрирована в нескольких валидационных исследованиях, особенно в биомедицине, оценивая его производительность через автоматизированные бенчмарки, экспертные обзоры и end-to-end эксперименты в мокрых лабораториях.
Автоматизированная и экспертная оценка: На сложном бенчмарке GPQA внутренний Elo рейтинг системы показал согласованность с точностью ее результатов, достигнув top-1 точности 78.4% на сложном "diamond set". Анализ более чем 200 исследовательских целей продемонстрировал, что масштабирование test-time compute последовательно улучшает качество гипотез, измеряемое Elo рейтингом. На кураторском наборе из 15 сложных проблем AI со-ученый превзошел другие современные AI модели и "лучшие предположения" решений, предоставленных человеческими экспертами. В небольшой оценке биомедицинские эксперты оценили выходные данные со-ученого как более новаторские и влиятельные по сравнению с другими базовыми моделями. Предложения системы по перепрофилированию лекарств, оформленные как страницы NIH Specific Aims, также были оценены как высококачественные панелью из шести экспертов-онкологов.
End-to-End экспериментальная валидация:
Перепрофилирование лекарств: Для острого миелоидного лейкоза (AML) система предложила новые кандидаты на лекарственные препараты. Некоторые из них, такие как KIRA6, были полностью новыми предложениями без предварительных доклинических доказательств использования при AML. Последующие in vitro эксперименты подтвердили, что KIRA6 и другие предложенные лекарства ингибировали жизнеспособность опухолевых клеток в клинически релевантных концентрациях в нескольких клеточных линиях AML.
Открытие новых мишеней: Система выявила новые эпигенетические мишени для фиброза печени. Лабораторные эксперименты с использованием человеческих печеночных органоидов валидировали эти находки, показав, что лекарства, нацеленные на предложенные эпигенетические модификаторы, имели значительную антифибротическую активность. Один из выявленных препаратов уже одобрен FDA для другого состояния, открывая возможность для перепрофилирования.
Устойчивость к антимикробным препаратам: AI со-ученый независимо воспроизвел неопубликованные экспериментальные находки. Ему была поставлена задача объяснить, почему определенные мобильные генетические элементы (cf-PICIs) обнаруживаются в многих видах бактерий. За два дня топ-ранжированная гипотеза системы заключалась в том, что cf-PICIs взаимодействуют с разнообразными фаговыми хвостами для расширения их диапазона хозяев. Это отражало новое, экспериментально валидированное открытие, к которому независимая исследовательская группа пришла после более чем десятилетия исследований.
Дополнение и ограничения: Философия дизайна AI со-ученого подчеркивает дополнение, а не полную автоматизацию человеческих исследований. Исследователи взаимодействуют с системой и направляют ее через естественный язык, предоставляя обратную связь, внося свои собственные идеи и направляя исследовательские процессы AI в коллаборативной парадигме "ученый в контуре". Однако система имеет некоторые ограничения. Ее знания ограничены зависимостью от литературы открытого доступа, потенциально упуская критическую предыдущую работу за платными барьерами. Она также имеет ограниченный доступ к негативным экспериментальным результатам, которые редко публикуются, но критически важны для опытных ученых. Кроме того, система наследует ограничения от базовых LLM, включая потенциал для фактических неточностей или "галлюцинаций".
Безопасность: Безопасность является критическим соображением, и система включает множественные меры предосторожности. Все исследовательские цели проверяются на безопасность при вводе, и сгенерированные гипотезы также проверяются для предотвращения использования системы для небезопасных или неэтичных исследований. Предварительная оценка безопасности с использованием 1200 адверсариальных исследовательских целей показала, что система может надежно отклонять опасные вводы. Для обеспечения ответственной разработки система становится доступной большему количеству ученых через Программу доверенных тестеров для сбора реальной обратной связи.
Практический пример кода
Рассмотрим конкретный пример agentic AI для исследования и открытия в действии: Agent Laboratory, проект, разработанный Сэмюэлем Шмидгаллом под лицензией MIT.
"Agent Laboratory" - это фреймворк автономного исследовательского рабочего процесса, предназначенный для дополнения человеческих научных усилий, а не их замены. Эта система использует специализированные LLM для автоматизации различных этапов научного исследовательского процесса, тем самым позволяя человеческим исследователям посвящать больше когнитивных ресурсов концептуализации и критическому анализу.
Фреймворк интегрирует "AgentRxiv" - децентрализованный репозиторий для автономных исследовательских агентов. AgentRxiv облегчает депонирование, извлечение и развитие исследовательских результатов.
Agent Laboratory направляет исследовательский процесс через отдельные фазы:
Обзор литературы: В течение этой начальной фазы специализированные агенты, управляемые LLM, получают задачу автономного сбора и критического анализа соответствующей научной литературы. Это включает использование внешних баз данных, таких как arXiv, для идентификации, синтеза и категоризации релевантных исследований, эффективно создавая всеобъемлющую базу знаний для последующих этапов.
Экспериментирование: Эта фаза охватывает коллаборативную формулировку экспериментальных дизайнов, подготовку данных, выполнение экспериментов и анализ результатов. Агенты используют интегрированные инструменты, такие как Python для генерации и выполнения кода, и Hugging Face для доступа к моделям, для проведения автоматизированного экспериментирования. Система предназначена для итеративного уточнения, где агенты могут адаптировать и оптимизировать экспериментальные процедуры на основе результатов в реальном времени.
Написание отчетов: В финальной фазе система автоматизирует генерацию всеобъемлющих исследовательских отчетов. Это включает синтез находок из фазы экспериментирования с инсайтами из обзора литературы, структурирование документа согласно академическим конвенциям и интеграцию внешних инструментов, таких как LaTeX, для профессионального форматирования и генерации рисунков.
Обмен знаниями: AgentRxiv - это платформа, позволяющая автономным исследовательским агентам делиться, получать доступ и коллаборативно продвигать научные открытия. Она позволяет агентам строить на основе предыдущих находок, способствуя кумулятивному исследовательскому прогрессу.
Модульная архитектура Agent Laboratory обеспечивает вычислительную гибкость. Цель состоит в повышении исследовательской продуктивности путем автоматизации задач при сохранении человеческого исследователя.
Анализ кода: Хотя всеобъемлющий анализ кода выходит за рамки этой книги, я хочу предоставить вам некоторые ключевые инсайты и поощрить вас самостоятельно углубиться в код.
Оценка: Для эмуляции человеческих оценочных процессов система использует трехсторонний agentic механизм суждения для оценки выходных данных. Это включает развертывание трех различных автономных агентов, каждый настроенный для оценки продукции с определенной перспективы, тем самым коллективно имитируя нюансированную и многогранную природу человеческого суждения. Этот подход позволяет более надежную и всеобъемлющую оценку, выходя за рамки единичных метрик для захвата более богатой качественной оценки.
class ReviewersAgent:
def __init__(self, model="gpt-4o-mini", notes=None, openai_api_key=None):
if notes is None:
self.notes = []
else:
self.notes = notes
self.model = model
self.openai_api_key = openai_api_key
def inference(self, plan, report):
reviewer_1 = "You are a harsh but fair reviewer and expect good experiments that lead to insights for the research topic."
review_1 = get_score(
outlined_plan=plan,
latex=report,
reward_model_llm=self.model,
reviewer_type=reviewer_1,
openai_api_key=self.openai_api_key
)
reviewer_2 = "You are a harsh and critical but fair reviewer who is looking for an idea that would be impactful in the field."
review_2 = get_score(
outlined_plan=plan,
latex=report,
reward_model_llm=self.model,
reviewer_type=reviewer_2,
openai_api_key=self.openai_api_key
)
reviewer_3 = "You are a harsh but fair open-minded reviewer that is looking for novel ideas that have not been proposed before."
review_3 = get_score(
outlined_plan=plan,
latex=report,
reward_model_llm=self.model,
reviewer_type=reviewer_3,
openai_api_key=self.openai_api_key
)
return f"Reviewer #1:\n{review_1}, \nReviewer #2:\n{review_2}, \nReviewer #3:\n{review_3}"Агенты суждения разработаны с определенным промптом, который тесно эмулирует когнитивный фреймворк и критерии оценки, обычно используемые человеческими рецензентами. Этот промпт направляет агентов анализировать выходные данные через призму, похожую на то, как это делал бы человеческий эксперт, рассматривая такие факторы, как релевантность, когерентность, фактическая точность и общее качество. Создавая эти промпты для отражения человеческих протоколов обзора, система стремится достичь уровня оценочной сложности, который приближается к человекоподобному различению.
def get_score(outlined_plan, latex, reward_model_llm, reviewer_type=None, attempts=3, openai_api_key=None):
e = str()
for _attempt in range(attempts):
try:
template_instructions = """
Respond in the following format:
THOUGHT:
<THOUGHT>
REVIEW JSON:
```json
<JSON>
```
In <THOUGHT>, first briefly discuss your intuitions
and reasoning for the evaluation.
Detail your high-level arguments, necessary choices
and desired outcomes of the review.
Do not make generic comments here, but be specific
to your current paper.
Treat this as the note-taking phase of your review.
In <JSON>, provide the review in JSON format with
the following fields in the order:
- "Summary": A summary of the paper content and
its contributions.
- "Strengths": A list of strengths of the paper.
- "Weaknesses": A list of weaknesses of the paper.
- "Originality": A rating from 1 to 4
(low, medium, high, very high).
- "Quality": A rating from 1 to 4
(low, medium, high, very high).
- "Clarity": A rating from 1 to 4
(low, medium, high, very high).
- "Significance": A rating from 1 to 4
(low, medium, high, very high).
- "Questions": A set of clarifying questions to be
answered by the paper authors.
- "Limitations": A set of limitations and potential
negative societal impacts of the work.
- "Ethical Concerns": A boolean value indicating
whether there are ethical concerns.
- "Soundness": A rating from 1 to 4
(poor, fair, good, excellent).
- "Presentation": A rating from 1 to 4
(poor, fair, good, excellent).
- "Contribution": A rating from 1 to 4
(poor, fair, good, excellent).
- "Overall": A rating from 1 to 10
(very strong reject to award quality).
- "Confidence": A rating from 1 to 5
(low, medium, high, very high, absolute).
- "Decision": A decision that has to be one of the
following: Accept, Reject.
For the "Decision" field, don't use Weak Accept,
Borderline Accept, Borderline Reject, or Strong Reject.
Instead, only use Accept or Reject.
This JSON will be automatically parsed, so ensure
the format is precise.
"""В этой multi-agent системе исследовательский процесс структурирован вокруг специализированных ролей, отражая типичную академическую иерархию для оптимизации рабочего процесса и оптимизации выходных данных.
Professor Agent: Professor Agent функционирует как основной исследовательский директор, ответственный за установление исследовательской повестки дня, определение исследовательских вопросов и делегирование задач другим агентам. Этот агент устанавливает стратегическое направление и обеспечивает соответствие целям проекта.
class ProfessorAgent(BaseAgent):
def __init__(self, model="gpt4omini", notes=None, max_steps=100, openai_api_key=None):
super().__init__(model, notes, max_steps, openai_api_key)
self.phases = ["report writing"]
def generate_readme(self):
sys_prompt = f"""You are {self.role_description()} \n Here is the written paper \n{self.report}. Task instructions: Your goal is to integrate all of the knowledge, code, reports, and notes provided to you and generate a readme.md for a github repository."""
history_str = "\n".join([_[1] for _ in self.history])
prompt = (
f"""History: {history_str}\n{'~' * 10}\n"""
f"Please produce the readme below in markdown:\n"
)
model_resp = query_model(
model_str=self.model,
system_prompt=sys_prompt,
prompt=prompt,
openai_api_key=self.openai_api_key
)
return model_resp.replace("```markdown", "")PostDoc Agent: Роль PostDoc Agent заключается в выполнении исследования. Это включает проведение обзоров литературы, проектирование и реализацию экспериментов, и генерацию исследовательских выходных данных, таких как статьи. Важно, что PostDoc Agent имеет способность писать и выполнять код, обеспечивая практическую реализацию экспериментальных протоколов и анализа данных. Этот агент является основным производителем исследовательских артефактов.
class PostdocAgent(BaseAgent):
def __init__(self, model="gpt4omini", notes=None, max_steps=100, openai_api_key=None):
super().__init__(model, notes, max_steps, openai_api_key)
self.phases = ["plan formulation", "results interpretation"]
def context(self, phase):
sr_str = str()
if self.second_round:
sr_str = (
f"The following are results from the previous experiments\n",
f"Previous Experiment code: {self.prev_results_code}\n"
f"Previous Results: {self.prev_exp_results}\n"
f"Previous Interpretation of results: {self.prev_interpretation}\n"
f"Previous Report: {self.prev_report}\n"
f"{self.reviewer_response}\n\n\n"
)
if phase == "plan formulation":
return (
sr_str,
f"Current Literature Review: {self.lit_review_sum}",
)
elif phase == "results interpretation":
return (
sr_str,
f"Current Literature Review: {self.lit_review_sum}\n"
f"Current Plan: {self.plan}\n"
f"Current Dataset code: {self.dataset_code}\n"
f"Current Experiment code: {self.results_code}\n"
f"Current Results: {self.exp_results}"
)
return ""Reviewer Agents: Reviewer агенты выполняют критические оценки исследовательских выходных данных от PostDoc Agent, оценивая качество, валидность и научную строгость статей и экспериментальных результатов. Эта фаза оценки эмулирует процесс peer-review в академических настройках для обеспечения высокого стандарта исследовательских выходных данных перед финализацией.
ML Engineering Agents: Machine Learning Engineering Agents служат как инженеры машинного обучения, участвуя в диалогической коллаборации с PhD студентом для разработки кода. Их центральная функция - генерировать несложный код для предобработки данных, интегрируя инсайты, полученные из предоставленного обзора литературы и экспериментального протокола. Это гарантирует, что данные соответствующим образом отформатированы и подготовлены для назначенного эксперимента.
"You are a machine learning engineer being directed by a PhD student who will help you write the code, and you can interact with them through dialogue.\n"
"Your goal is to produce code that prepares the data for the provided experiment. You should aim for simple code to prepare the data, not complex code. You should integrate the provided literature review and the plan and come up with code to prepare data for this experiment.\n"SWEngineerAgents: Software Engineering Agents направляют Machine Learning Engineer Agents. Их основная цель - помочь Machine Learning Engineer Agent в создании простого кода подготовки данных для конкретного эксперимента. Software Engineer Agent интегрирует предоставленный обзор литературы и экспериментальный план, обеспечивая, что сгенерированный код является несложным и непосредственно релевантным исследовательским целям.
"You are a software engineer directing a machine learning engineer, where the machine learning engineer will be writing the code, and you can interact with them through dialogue.\n"
"Your goal is to help the ML engineer produce code that prepares the data for the provided experiment. You should aim for very simple code to prepare the data, not complex code. You should integrate the provided literature review and the plan and come up with code to prepare data for this experiment.\n"В заключение, "Agent Laboratory" представляет собой сложный фреймворк для автономных научных исследований. Он предназначен для дополнения человеческих исследовательских возможностей путем автоматизации ключевых исследовательских этапов и облегчения коллаборативной генерации знаний, управляемой AI. Система стремится повысить эффективность исследований путем управления рутинными задачами при сохранении человеческого надзора.
Краткий обзор
Что: AI агенты часто работают в рамках заранее определенных знаний, ограничивая их способность решать новые ситуации или открытые проблемы. В сложных и динамичных средах этой статической, заранее запрограммированной информации недостаточно для истинных инноваций или открытий. Фундаментальный вызов заключается в том, чтобы позволить агентам выйти за рамки простой оптимизации к активному поиску новой информации и выявлению "неизвестных неизвестных". Это требует смены парадигмы от чисто реактивного поведения к проактивному, agentic исследованию, которое расширяет собственное понимание и возможности системы.
Почему: Стандартизированное решение состоит в построении Agentic AI систем, специально разработанных для автономного исследования и открытия. Эти системы часто используют multi-agent фреймворк, где специализированные LLM сотрудничают для эмуляции процессов, подобных научному методу. Например, различные агенты могут получить задачи генерации гипотез, их критического обзора и развития наиболее перспективных концепций. Эта структурированная, коллаборативная методология позволяет системе интеллектуально навигировать в обширных информационных ландшафтах, проектировать и выполнять эксперименты, и генерировать подлинно новые знания. Автоматизируя трудоемкие аспекты исследования, эти системы дополняют человеческий интеллект и значительно ускоряют темп открытий.
Правило большого пальца: Используйте шаблон Исследования и Открытия при работе в открытых, сложных или быстро развивающихся областях, где пространство решений не полностью определено. Он идеален для задач, требующих генерации новых гипотез, стратегий или инсайтов, таких как научные исследования, анализ рынка и генерация творческого контента. Этот шаблон необходим, когда цель состоит в раскрытии "неизвестных неизвестных", а не просто оптимизации известного процесса.
Визуальное резюме
 Рис.2: Шаблон проектирования Исследование и Открытие
Рис.2: Шаблон проектирования Исследование и Открытие
Ключевые выводы
Исследование и Открытие в AI позволяют агентам активно преследовать новую информацию и возможности, что необходимо для навигации в сложных и развивающихся средах.
Системы, такие как Google Co-Scientist, демонстрируют, как Агенты могут автономно генерировать гипотезы и проектировать эксперименты, дополняя человеческие научные исследования.
Multi-agent фреймворк, проиллюстрированный специализированными ролями Agent Laboratory, улучшает исследования через автоматизацию обзора литературы, экспериментирования и написания отчетов.
В конечном счете, эти Агенты стремятся усилить человеческое творчество и решение проблем путем управления вычислительно интенсивными задачами, тем самым ускоряя инновации и открытия.
Заключение
В заключение, шаблон Исследования и Открытия является самой сущностью истинно agentic системы, определяя ее способность выйти за рамки пассивного следования инструкциям к проактивному исследованию своей среды. Этот врожденный agentic драйв - это то, что наделяет AI способностью работать автономно в сложных областях, не просто выполняя задачи, но независимо устанавливая подцели для раскрытия новой информации. Это продвинутое agentic поведение наиболее мощно реализуется через multi-agent фреймворки, где каждый агент воплощает определенную, проактивную роль в более крупном коллаборативном процессе. Например, высоко agentic система Google Co-scientist включает агентов, которые автономно генерируют, дебатируют и развивают научные гипотезы.
Фреймворки, такие как Agent Laboratory, дополнительно структурируют это путем создания agentic иерархии, которая имитирует человеческие исследовательские команды, позволяя системе самоуправлять всем жизненным циклом открытий. Ядро этого шаблона заключается в оркестровке эмерджентных agentic поведений, позволяя системе преследовать долгосрочные, открытые цели с минимальным человеческим вмешательством. Это возвышает партнерство человек-AI, позиционируя AI как подлинного agentic коллаборатора, который обрабатывает автономное выполнение исследовательских задач. Делегируя эту проактивную исследовательскую работу agentic системе, человеческий интеллект значительно дополняется, ускоряя инновации. Разработка таких мощных agentic способностей также требует сильной приверженности безопасности и этическому надзору. В конечном счете, этот шаблон предоставляет чертеж для создания истинно agentic AI, трансформируя вычислительные инструменты в независимых, целеустремленных партнеров в поиске знаний.
Ссылки
Дилемма исследования-эксплуатации: Фундаментальная проблема в обучении с подкреплением и принятии решений в условиях неопределенности. https://en.wikipedia.org/wiki/Exploration–exploitation_dilemma
Google Co-Scientist: https://research.google/blog/accelerating-scientific-breakthroughs-with-an-ai-co-scientist/
Agent Laboratory: Using LLM Agents as Research Assistants https://github.com/SamuelSchmidgall/AgentLaboratory
AgentRxiv: Towards Collaborative Autonomous Research: https://agentrxiv.github.io/
Навигация
Назад: Глава 20. Приоритизация
Вперед: Приложение A. Продвинутые техники промптинга